| 编者按:大数据在城市研究中的应用方兴未艾。社交媒体、电话、交通卡等等数据的出现极大地丰富了城市研究的粒度和广度,使得以前因为数据获取困难而不能研究的对象变得可研究。这篇文章认为,大数据仍然是数据的一种,其本质上还是对事物现象和问题的观测结果。而数据只有在它有用时才重要,它不能替代城市研究中的常识、理论还有严密的研究设计,城市研究在使用大数据时需遵循科学研究中严谨严密的数据收集方法和研究设计。 |
文献来源:Liu, J., Li, J., Li, W., & Wu, J. (2015). Rethinking big data: A review on the data quality and usage issues. ISPRS Journal of Photogrammetry and Remote Sensing. doi: 10.1016/j.isprsjprs.2015.11.006.
大数据的权威性问题
传统的数据收集方式一般都是由研究者或者国家、某一个社会机构、团体来执行或者监督执行的。数据的真实性、可信度以及后续数据的处理包括数据中错误的剔除都是基于一个假设,即研究者严格遵从研究伦理。一般而言,社会上,也包括学术界,对国家、社会机构以及相关团体收集的数据是有着较高的认可度和信任,因为这些执行数据收集的机构具有权威性和公信力,而且这些机构也往往有更多的资源和力量去执行这些基础工作。
但是众多的大数据的收集在权威性和公信力这方面存在问题。我们在研究中所使用的社交媒体数据来自新浪微博、腾讯微博等社交平台,这些平台并不是以科学研究为目的而存在的,而是以逐利为目的的商业化平台。这里面的区别有三个方面:第一,商业化平台并不会遵循科学的数据收集程序包括抽样方法等去收集和保存数据,他们只服务于能够提供利润的人群而不是总体,而且他们提供的数据服务接口背后的抽样方法和处理算法未知,这些重要信息对研究者来说是一个黑箱,比如大众点评网、街旁网的用户人群;其次,这些大数据提供者可能会随时改变数据属性变量以及收集的方法,而这些变化研究者可能无从得知;第三,商业化平台没有义务和利润动机去保证数据的真实性和有效性,一个典型的例子就是新浪微博上的众多僵尸粉和广告粉。其他网络数据源,如飞信好友、搜房网、百度、谷歌搜索等等,也存在这些问题。
著名的谷歌流感趋势指数Google Flu Trends index,能够利用用户搜索流感数据记录来预测流感爆发时间,曾经轰动一时,但是有学者曾经报告谷歌改动算法使得预测结果精度变得不稳定。
大数据的信息片面和噪音问题
大数据的信息片面性体现在大数据所含信息的片面性。大数据所能揭示的信息比较片面,并不完全。比如手机数据覆盖人群范围大,实时且低成本,但基站定位信息粗略,且无用户属性信息,应用范围有限。
第一个限制在于因为目前已有手机数据往往只有包括用户ID、基站位置、时间戳等少数几个字段的研究,这些在单个用户水平的数据记录往往因为没有用户的社会属性数据而变得应用极为有限。这些数据不能体现被调查者之间的差异,难以描述居民出行行为特征。就本文目前查阅文献所得,这些数据也就主要用在识别人群活动位置及其移动性,比如用户居住地、城市中心识别、城市交通流量、空间交互社区等。
二是这些位置也并非准确的用户活动地点,而只是基站位置。这些位置的精确度也受基站的密集度和信号强弱的影响。三是数据所擅长的活动识别方面,只能识别工作和居住这两种活动,这两类活动的识别也因为武断的自定义活动时间段而变得不准确。而且数据只记录了用户的移动行为,这些移动行为往往只花了用户很少时间,而用户真正花时间的活动,如在办公室的工作、在居住小区的生活,却被忽略了。用户的这些停留期间的活动,才是真正与城市居民行为、健康、社会经济等息息相关的活动,手机定位数据记录的只是这些海量信息里面一些极片面的相对不重要的信息。
公交刷卡数据的应用也是如此。即使研究者利用传统的居民出行调查数据和土地利用数据来确定公交IC卡持卡人的社会经济属性,这种利用其他数据来协助识别持卡人居住地可能存在极大的误差。这些问题也存在于街旁网的位置签到数据。因为其商业化的本质,所记录的位置信息和用户签到信息都是基于商业消费活动的。使用街旁网数据也就仅仅限于研究城市的商业活动。准确来说,是已经在街旁网注册登记的那些商户和用户所参与的商业活动,一般而言,是一些零售业、大众消费类的商业活动。类似的大数据包括大众点评网签到数据。
大数据的样本代表片面性问题
正如在大数据的权威性问题中所阐述的,众多的大数据提供者因为其商业化逐利的本质,大数据的收集过程中很可能没有采用正确的抽样方式或者说所代表的人群局限在一个很小的范围内。根据这些大数据做出了研究成果很可能没有反映真实的问题和情况。
目前很多使用社交媒体数据的研究都是基于这样一种假设:社交媒体数据由于其数据量特别大,使用的用户(网民)特别多,似乎具有较大的样本覆盖率,因此就可以忽略因为其商业化平台带来的人群样本偏差。但是实际情况却并不是这样。比如,新浪微博2013 年第四季度的日活跃用户为6140 万人,根据中国互联网络信息中心的网民数量统计,大约占网民人数的9.94%,占国内总人口的4.51%,从这个角度,其样本覆盖率仍然是很低的。而且一个对新浪微博用户的抽样调查显示,超过四分之一的微博用户集中在广东、北京和上海,而这三个地方的网民却只占全国网民数量的9%。国外的数据也存在类似的问题。2012年一项对1802名美国网民的抽样调查表明,国外社交网络网站Twitter只有16%的网民使用率,而且只有年龄从18岁到29岁的年轻人、非洲裔美国人和城市居民对此感兴趣。当前非常热门的照片分享社交媒体网站Instagram有13%的使用率,除了上述群体,也只在拉美人和女性中流行。
手机的数据也存在样本代表性的问题。目前已有的手机数据是某一家移动通信运营商提供的与之签订了商业合同的用户手机数据。但一个城市内还有很多没有与移动通信运营商签订合同的用户以及与其他运营商签订合同的手机用户,这些用户的手机通讯信息和活动并没有被这些数据所记录。
大数据的出现带来了传统地理学和城市研究数据获取方式的变革,但是同时也带来了大数据狭窄的人群代表性。传统的数据收集方法,如问卷调查、访谈等方式,虽然有着自我报告、数据输入失误等种种问题,但在统计方法上和研究意义上,都已经很好的被证明是一种可靠的收据收集方法。
大数据的可靠性问题
数据的可靠性在于两点:一、数据是否能够体现真实的研究对象特征,而不是掺杂了研究者或者数据收集者自己的影响;二、数据是否具有一定的稳定性和一致性,不会随着其他无关因素变化。大数据在这两方面则存在问题。同样以社交网络数据为例,在以社交网络数据为研究数据时往往会忽视社交网络背后的运营公司,而这些运营公司本身就是一个影响研究结果的重要变量,他们的行为影响着每一个基于这些数据的研究。比如,研究各个城市之间的微博联系,研究者容易忽略的问题是,微博平台本身会根据用户的出生地、性别、大学等属性进行好友推荐(见下图1),正如百度的精准广告投放。这些运营公司施加的隐藏在背后的影响直接改变了这些所谓的城市间交互网络分析和城市间的网络空间分析。就数据层面来说,这些大数据里面的数字所表现的不仅有我们原本打算研究的对象,也就是城市之间、区域之间居民的交互活动,也有这些社交网络平台背后的影响。一言以蔽之,社交媒体等类型的大数据在表现用户行为活动上并不可靠。
图1-新浪微博平台通过好友推荐等方式影响真实的社交网络。图片来源:编者
再以网络搜索引擎数据为例。一些搜索引擎的自动条目完成,本意是帮助用户更快更好的完成搜索任务,但是这个功能的设置无意之中却对用户的真实行为意图进行了扭曲(图2)
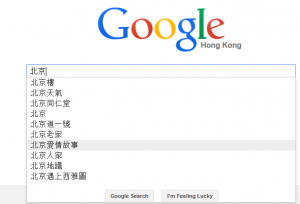
图2- Google搜索引擎的自动完成功能歪曲用户真正想搜索的内容。图片来源:编者
大数据的不可靠还体现在大数据的数据收集或者提交方式上。比如用户在新浪微博上进行签到,无论是网页还是手机移动客户端,用户其实都可以选择在哪个地点进行签到,用户本人在香港香港大学,可以选择在北京的北京大学签到(见图3)。这种没有通过验证的数据收集和提交方式使得基于这些数据的研究成果可信度大打折扣。
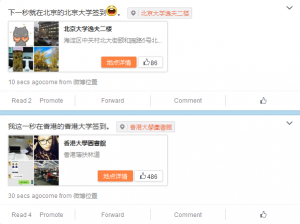
图3-新浪微博的位置微博可以不经过验证位置即可发出。图片来源:编者
大数据的不可靠还在于其数据的不稳定性和不一致性。比如微博有效用户数量因为其他社交网络平台和用户趣味的影响而潮起潮落,直接影响了其用户的人口组成结构。基于这些社交媒体数据的研究结果在几个月前可能是成立的,但到现在却不成立了。
又如著名的开源地图提供者OpenStreetMap,是众多研究者心目中的不错的免费地图数据。然而因为OpenStreetMap中各类地图要素都是未经过专门训练的用户自我报告而生成的数据,这些数据因为没有采用统一的数据收集方法和标准,导致每个地方的数据完整度和数据质量都非常不同。而且,与权威的政府测绘数据相比,其地图要素的定位精度不是十分理想。因为OpenStreetMap是各个志愿者在GPS仪器和雅虎遥感影像的协助下采集数据的,其定位精度不会超过GPS和雅虎遥感影像。研究OpenStreetMap数据质量的知名学者Muki Haklay指出伦敦OpenStreetMap数据的地图定位精度只有20米,他认为研究者只能把OpenStreetMap当作一个“笼统概括性的地图数据集”(generalized dataset)。还有一个有意思的发现是OpenStreetMap“欺贫爱富”:在比较富有的地方的地图数据十分丰富,但在贫穷的地区却十分稀少。一个比较合理的解释就是OpenStreetMap的地图志愿者们往往生活在在较富裕的地区,或者倾向于在这些富裕地区活动和采集数据。





刘建政
香港大学城市规划与设计系博士后研究员、剑桥大学土地经济系访问学者。本科毕业于华东师范大学地理信息系统专业;硕士毕业于北京大学城市与区域规划专业;博士毕业于香港大学城市规划与设计系。他的个人网站是http://www.jzliu.net/。